

Pandasのメソッドはここから
パンダをインポートする方法
import pandascsvをpandsフレームへ変換する

data = pandas.read_csv("ファイル名.csv")pandasでデータタイプを確認する
frameとはデータそのもの
csvをpandsでインポートした変数のtypeを調べてみます。
すると、「pandas.core.frame.DataFrame」というデータ型であることがわかります。
このデータ型はテーブルデータそのものをさします。
print(type(data))
# >>pandas.core.frame.DataFrame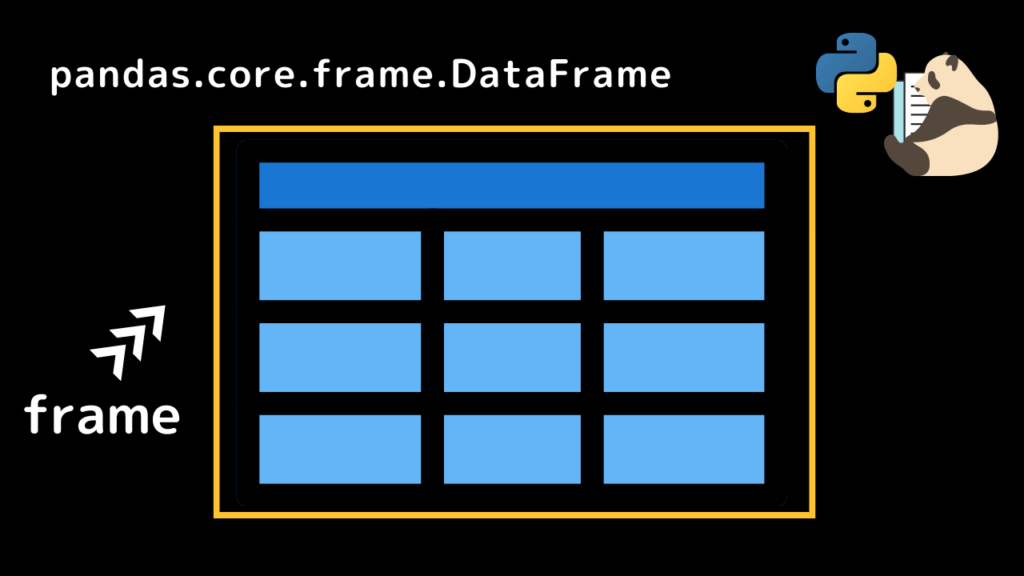
Seriesは列をさす
つぎに、pandasのデータフレームからどこかひとつの列を抽出してデータ型を調べます。
抽出方法は 変数名["列名"] もしくは 変数名.列名 で抽出できます。
例では、dataという変数名からtempという列を抽出しています。
すると、データ型は「pandas.core.series.Series」と表示されます。
これはテーブルの列データであることを示しています。
print(type(data["temp"]))
# >>pandas.core.series.Series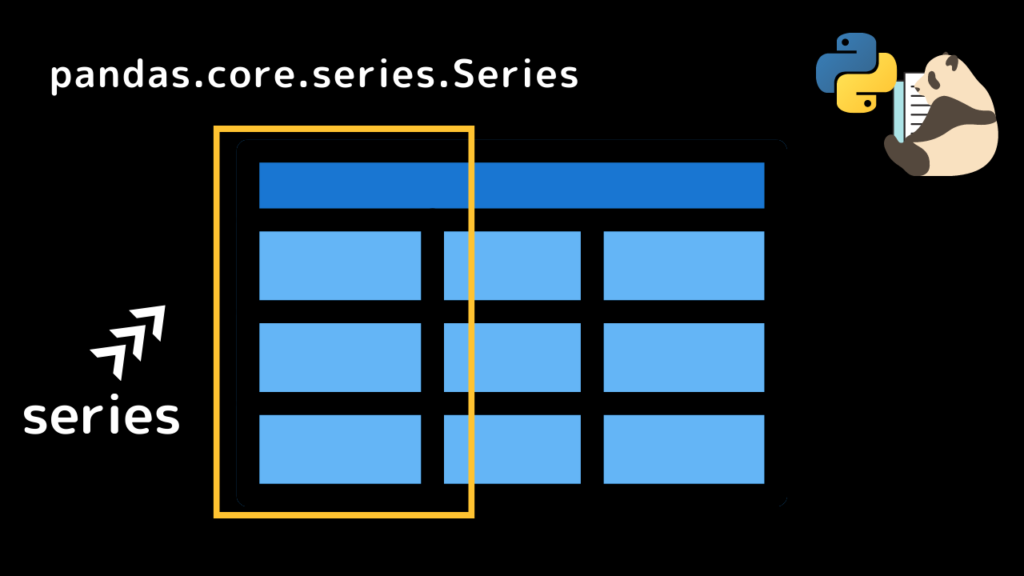
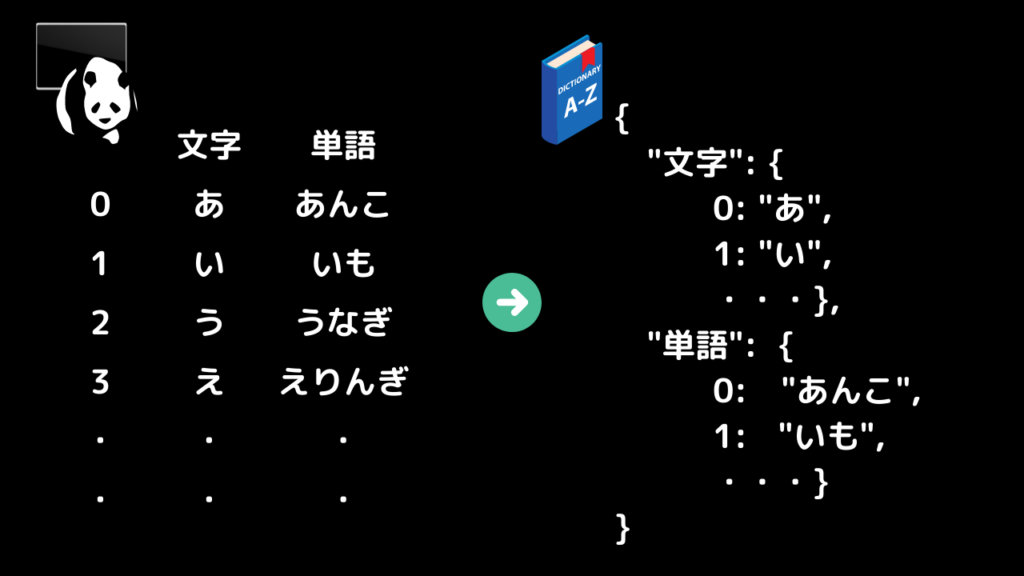
pandasフレームのデータをディクショナリーにする

# 1.pandasをインポート
import pandas
# 2.csvデータのフレーム化
data = pandas.read_csv("ファイル名.csv")
# 3.データの辞書化
data_dict = data.to_dict()
# printで確認
print(data_dict)左がフォーマットデータで右がオブジェクト化されたデータになります。
pandasでシリーズをリスト化する

data_list1 = data.列名.to_list()
print(data_list1)pandasで特定のリストだけ表示する
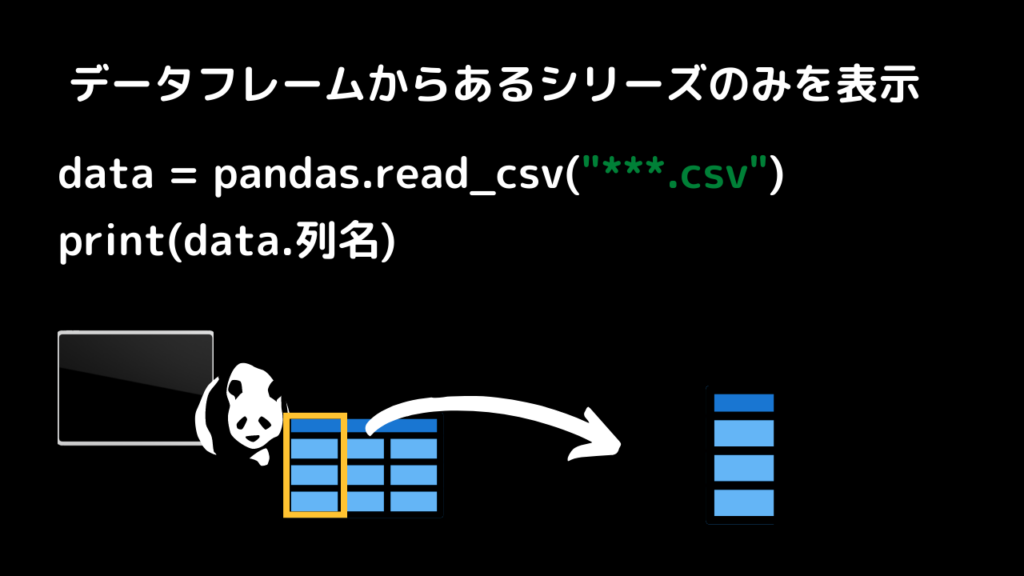
data = pandas.read_csv("ファイル名.csv")
print(data.列名)pandasでリストの平均を求める

scoreが一番高いレコードを表示する

data = pandas.read_csv("ファイル名.csv")
highest_score = data[data.列名 == data.列名.max()]
print(highest_score)pandasでリストデータをpandasフォーマットへ変換する
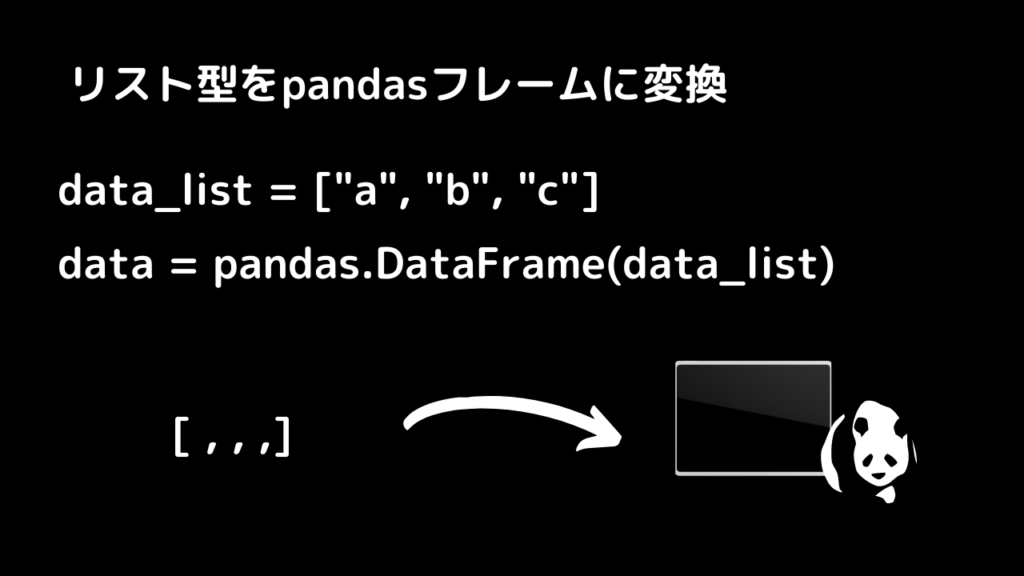
data_list = [18, 92, 32]
data = pandas.DataFrame(data_list)
print(data)pandasで辞書データをpandasフォーマットへ変換する

data_dict = {
"series1": ["a","b"],
"series2": ["c","d"]
}
data = pandas.DataFrame(data_dict)
print(data)pandasを使ってcsvファイルを作る

data = pandas.DataFrame(data_dict)
data.to_csv("new_data.csv")リストを加工して別のリストを作る
数字のリストを加工する
リストの数字それぞれから -1 する。

num_list = [1, 2, 3, 4, 5]
new_num_list = [num - 1 for num in num_list]
print(new_num_list)
# >> [0, 1, 2, 3, 4]文字列をリストにする
文字列 ”Vynsen” を1文字づつリストにする。

name = "Vynsen"
name_alphabets = [al for al in name]
print(name_alphabets)rangeからリストを作る
rangeで指定した範囲をリストにする。

numbers = [num for num in range(1,11)]
print(numbers)5文字以上の単語を抽出

names = ["Irving", "Autumn", "Jena", "Anna", "Elliot","Vanessa"]
long_names = [name for name in names if len(name) > 5]
print(long_names)辞書データを加工しよう
リストからディクショナリーを作る

import random
names = ["Irving", "Autumn", "Jena", "Anna", "Elliot","Vanessa"]
score_dict = {
name: random.randint(1, 100) for name in names
}
print(score_dict)辞書データを加工して別の辞書データを作ろう
生徒と得点のスコアのディクショナリーから一定の点数を取得した生徒を抽出する。
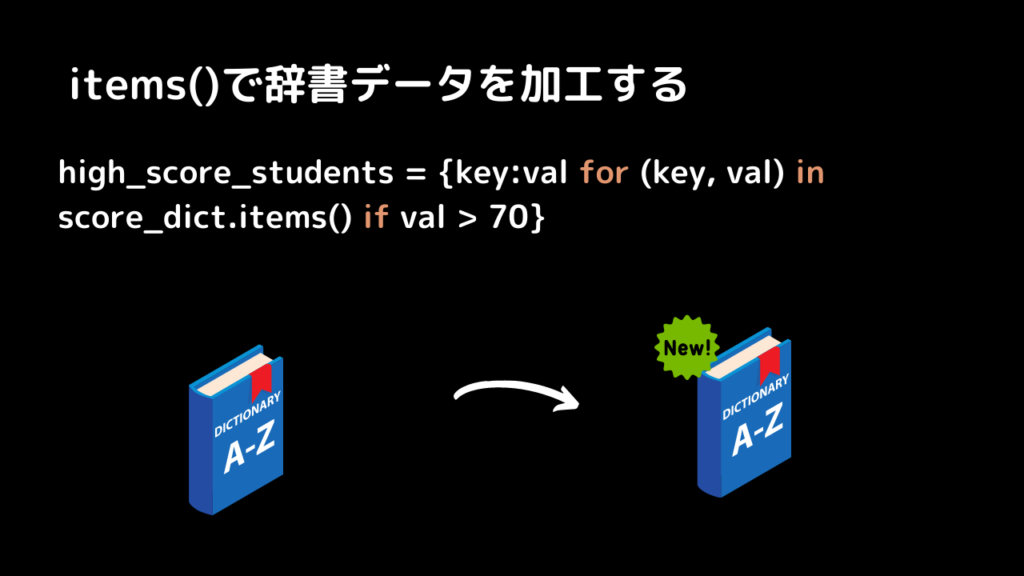
import random
names = ["Irving", "Autumn", "Jena", "Anna", "Elliot","Vanessa"]
score_dict = {
name: random.randint(1, 100) for name in names
}
high_score_students = {key:val for (key, val) in score_dict.items() if val > 70}
print(high_score_students)ディクショナリーの中身をループで確認しよう
student_dict = {
"student": ["Harry", "James", "Lily"],
"score": [80, 77, 100]
}
for (key, value) in student_dict.items():
print(key)
for (key, value) in student_dict.items():
print(value)
for (key, value) in student_dict.items():
print(key, value)pandasを使ってディクショナリからcsvを作る2
全体の流れ
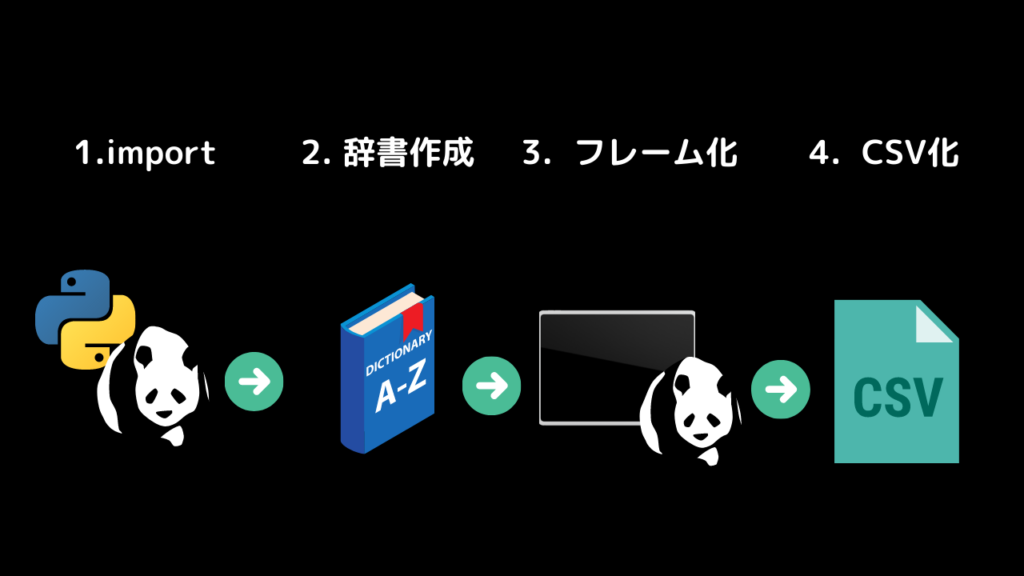
1.pandasをインポートします
2.辞書データを作成します

3.データをフレーム化します

4.CSVを出力します

# 1.pandasをインポートします
import pandas
# 2.辞書データを作成します
student_dict = {
"student": ["Harry", "James", "Lily"],
"score": [80, 77, 100]
}
# 3.データをフレーム化します
student_data_frame = pandas.DataFrame(student_dict)
# 4.CSVを出力します
student_data_frame.to_csv("new_data.csv")pandasを利用してcsvを辞書化する
以下のcsvデータを辞書化します。

前半で以下のようにcsvからフォーマットデータを作り、辞書化する方法を学びました。
今回は異なる辞書化をしたいと思います。
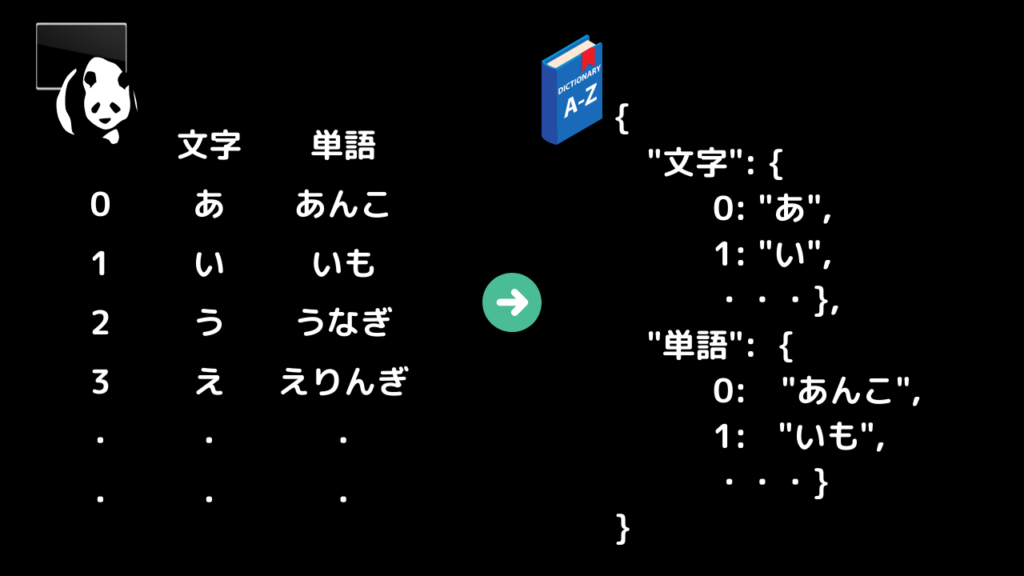
今回は以下のようにcsvデータを辞書化してみたいと思います。

ざっくり全体像を見ていきます。
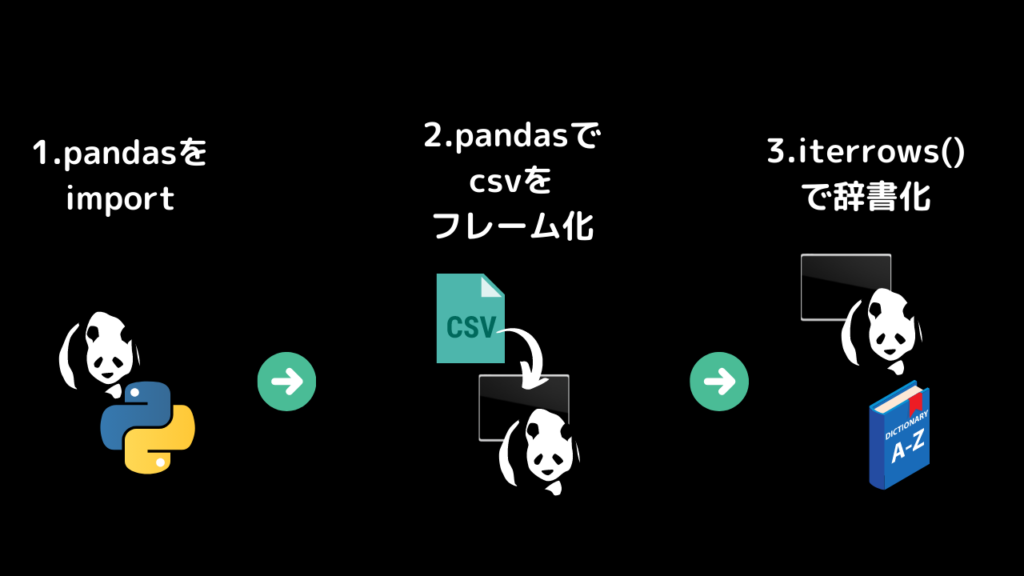
1.pandasをインポート
2.pandasでcsvファイルをデータフレーム化

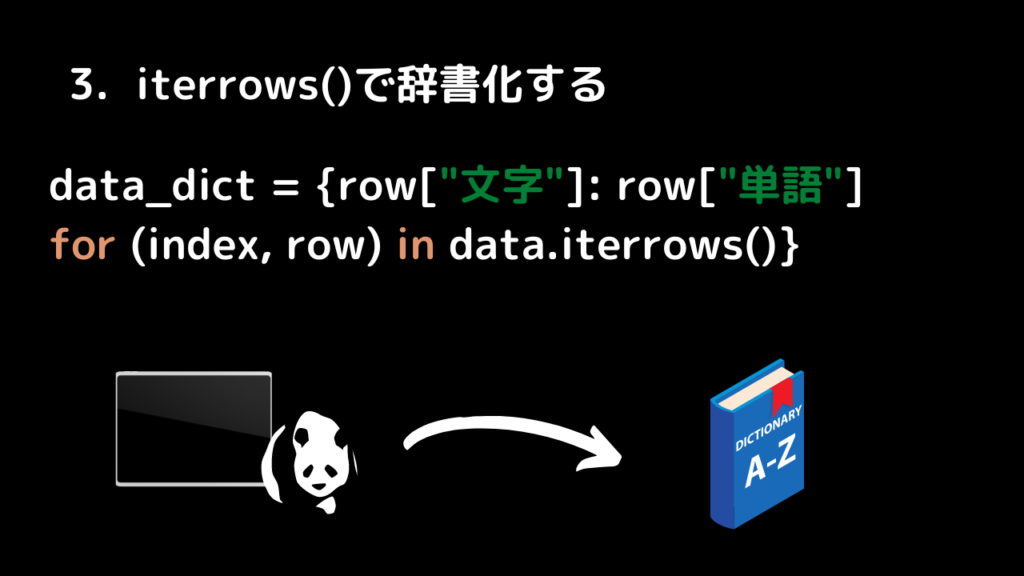
3. iterrows()で辞書化
iteration = 反復
rows = 行
# 1.pandasをインポート
import pandas
# 2.pandasでcsvファイルをデータフレーム化
data = pandas.read_csv("words.csv")
# 3. iterrows()で辞書化
data_dict = {row["文字"]: row["単語"] for (index, row) in data.iterrows()}
print(data_dict)iterrowsについて少し詳しく書きます。

pandasを使用せずcsvファイルを辞書化する
番外編でpandasを使用せずにcsvファイルを辞書化する方法を見ていきます。
全体像はざっくり以下のようになります。
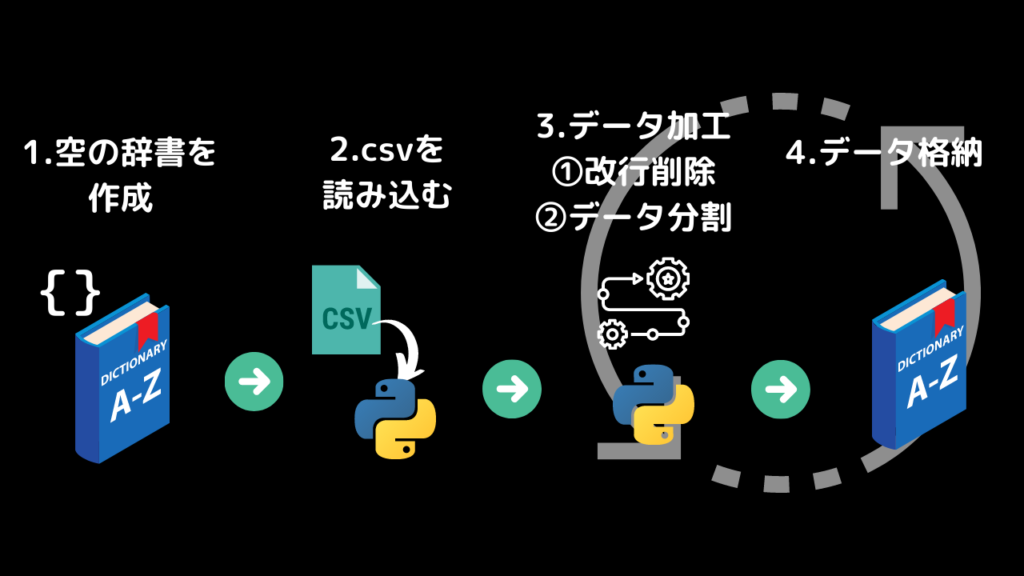
1.空の辞書データを作成します

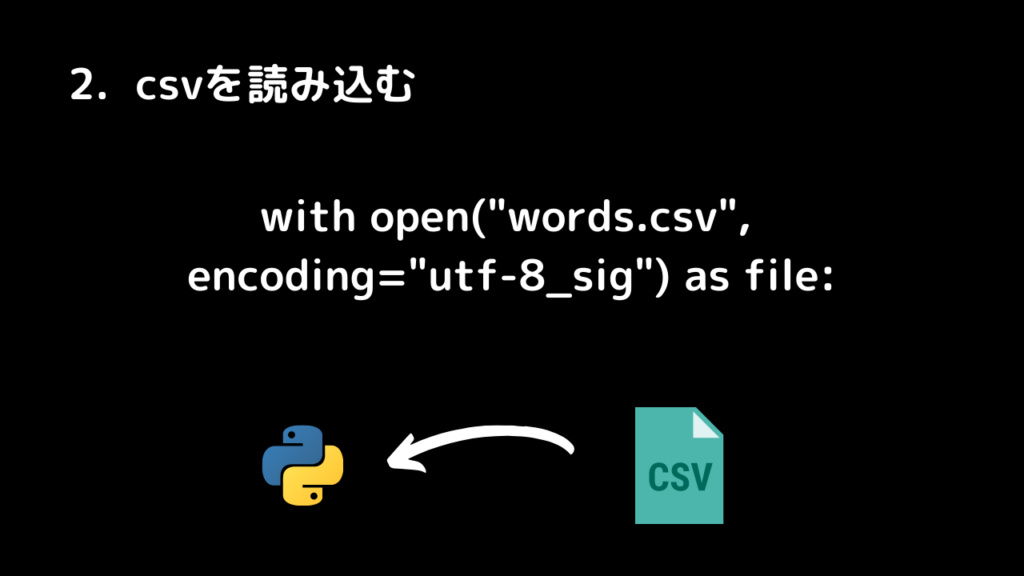
2.csvを読み込みます
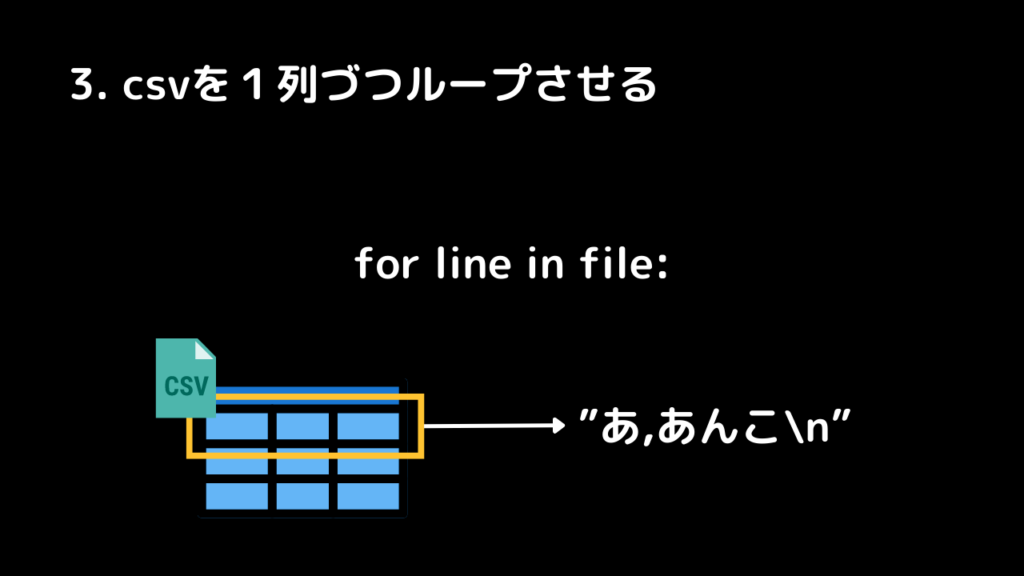
3.csvファイルを1行づつ抽出します
4. 「/n」改行を消します
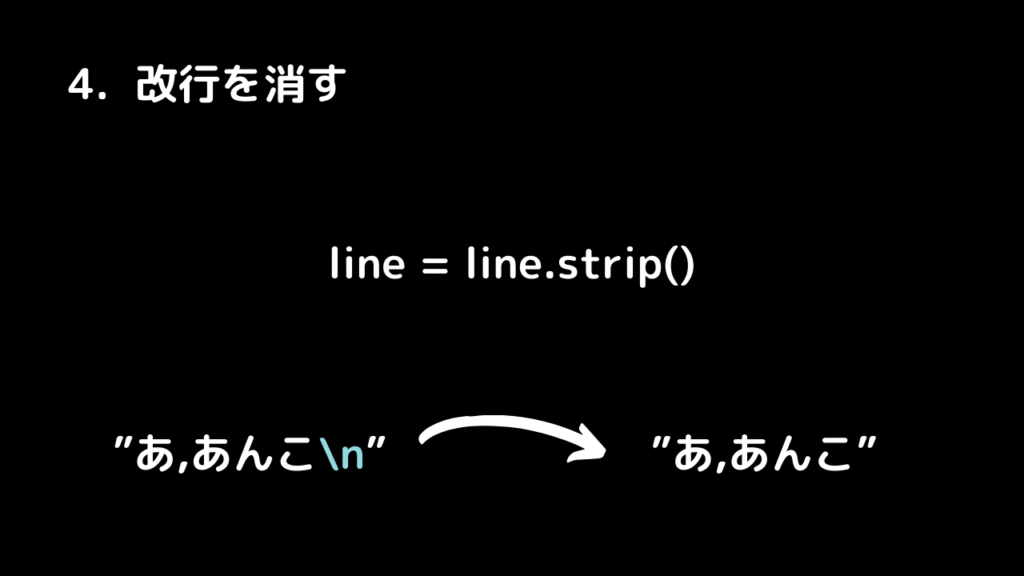
5.カンマの前後でデータを分割します

6.データを辞書へ格納していきます

# 1.空の辞書データを作成します
dict = {}
# 2.csvを読み込みます
with open("words.csv", encoding="utf-8_sig") as file:
# 3.csvファイルを1行づつ抽出します
for line in file:
# 4.「/n」改行を消します
line = line.strip()
# 5.カンマの前後でデータを分割します
(key, val) = line.split(",")
# 6.データを辞書へ格納していきます
dict[key] = val
print(dict)ぜひ参考にしてください!また!













